一通用文档的处理技术难点
- 种类繁多:非标文档的类型数量繁多,甚至对于同一家用户,数量也是很多的;这给OCR带来了不能按照传统的类别训练的方式来确定档案类别,因为数量太多了;传统的YOLO-V3的网络,一般按照每个类别5000张样本的规模进行标图、训练,时间在7天左右。但是数量太多的情况下,还采用这种方式,成本将是一个天文数字。
- 尺寸不一:有A3、A4、A5、卡片大小(身份证、银行卡)、各种手机拍照、截图;尺寸的不一,就给OCR带来了“不能按照固定位置”去裁切、去识别的技术挑战;
- 提取的内容格式各样:不同的文档提供的内容不一样,哪怕是同样的文档,不同的客户所提取的内容也有可能不一样。这就要求OCR必须提供一整套完备的、可以灵活配置的结构化内容提取方案。
二整体识别流程
系统建模流程:1)定义模板;2)定义标签
系统识别流程:
- 整体识别:全文识别、表格识别、一维码二维码识别、人脸识别;
- 文档类别筛选:比如身份证上有人脸,可以通过这个特征定义身份证;有些文档含有条码,可以按照是否有条码来判断此类文档类型
- 按照标签提取信息:固定位置提取、表格单元格提取、正则表格式逻辑提取。
- 结构化信息输出:json格式。
三文档类别的自动识别
OCR识别平台,能自动将任意文档中的全文、表格、一维码、二维码、是否有人脸等信息,通过这些信息的组合,可以顺利的将文档进行分类。只有先确定了文档的类别,才能进行结构化信息的抽取。
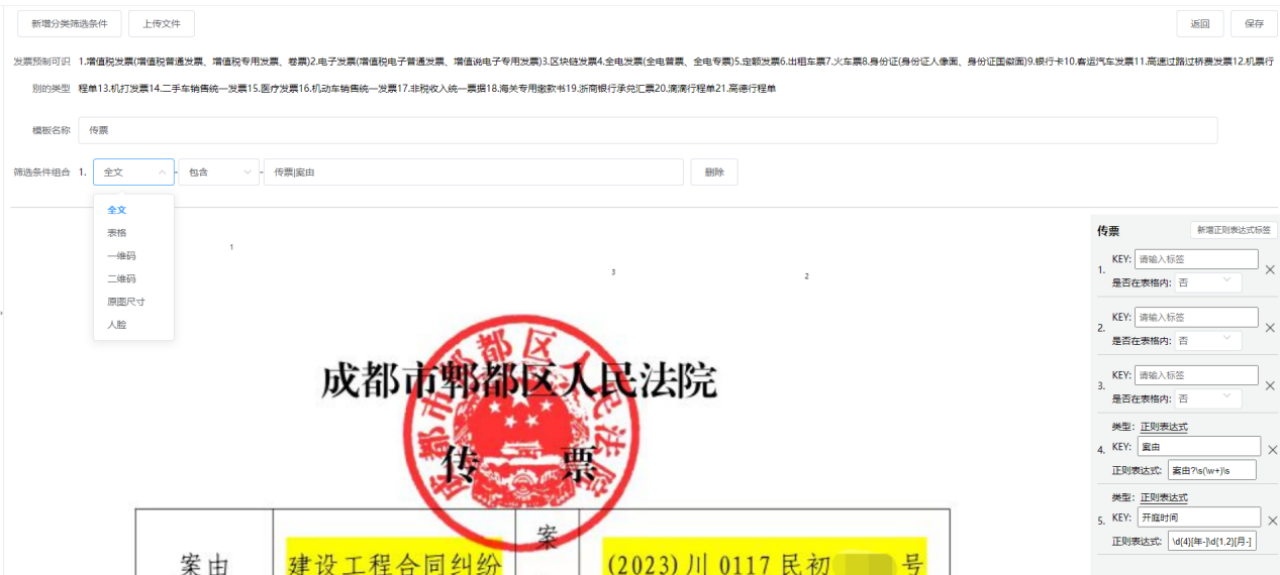
四通用文档要提取的内容的定义
对于特定文档的模板,系统支持自定义标签。
系统支持3中定义标签的方案:框选提取、表格中单元格提取、正则表格式提取。
对于下面的传票,我们可以采用正则表达式的方式提取,也可以采用单元格提取。
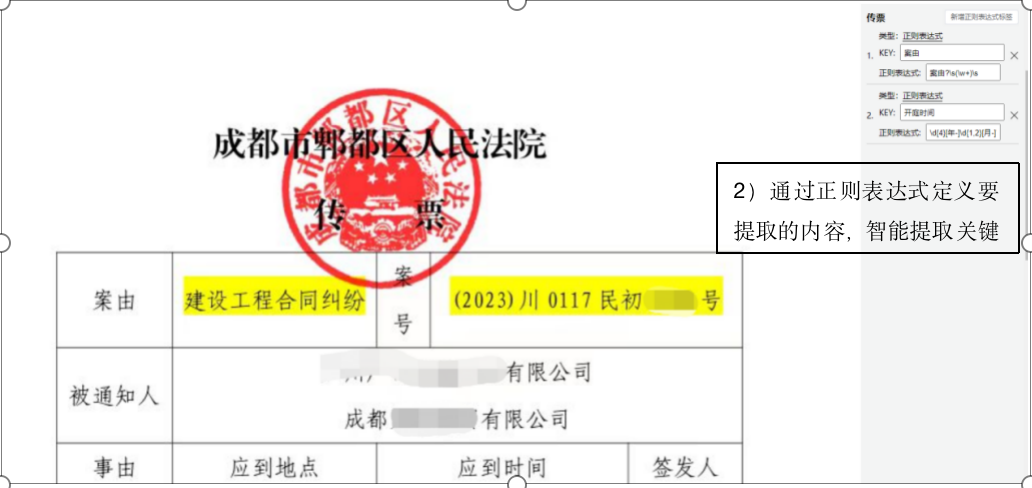
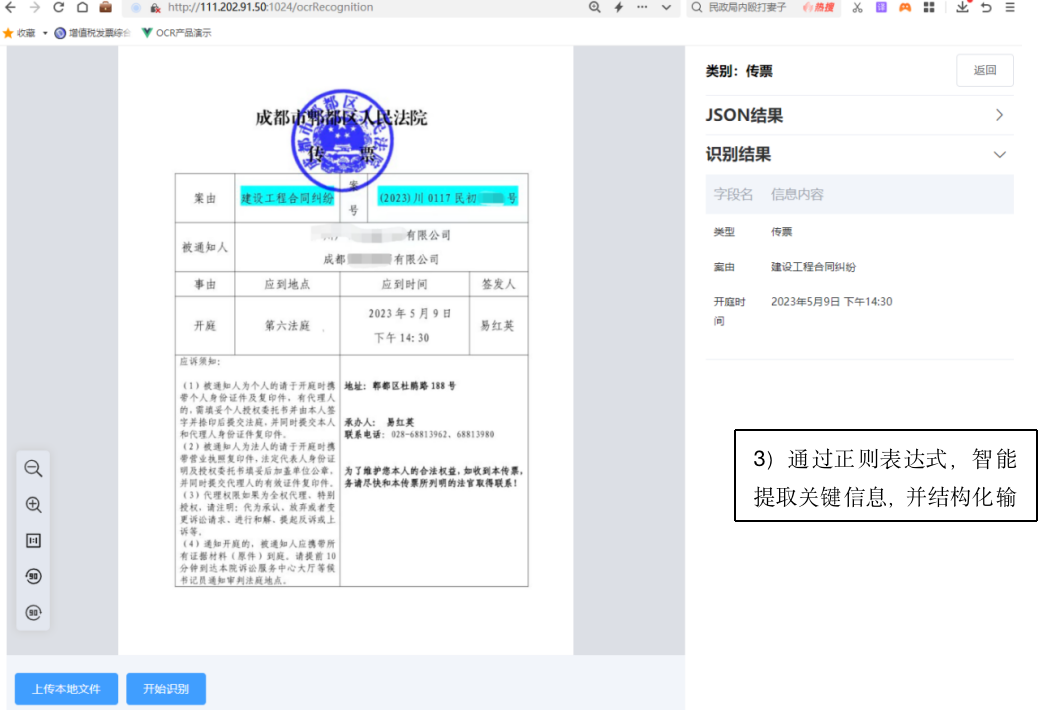
五智能识别文档,并结构化输出要提取的内容
对于已经定义好的文档类型,系统会自动识别类型,并按照定义好的标签进行结构化信息的输出。
六OCR产品平台技术优势
- 非常灵活的文档类型定义:可以支持多种数量(上不封顶)的文档类型定义;
- 基础识别功能强大、准确:全文识别(99.5%准确率)、表格识别(可识别是否有表格、表格的行数、列数、单元格内容)、一维码二维码识别(是否有一维码、二维码、一维码的value、二维码的value)、人脸(是否有人脸、人脸的位置);
- 灵活的标签定义:支持固定位置提取、单元格提取、正则表达式提取。
 京ICP备18058979号
京ICP备18058979号